*잠깐, 이 글을 소개해드리는 위시켓은 2019년 시밀러웹 방문자 수 기준, 국내 1위 IT아웃소싱 플랫폼입니다. 현재 8만 이상의 개발업체, 개발 프리랜서들이 활동하고 있으며, 무료로 프로젝트 등록이 가능합니다. 프로젝트 등록 한 번으로 여러 개발업체의 견적, 포트폴리오, 예상기간을 한 번에 비교해보세요:)
*잠깐, 이 글을 소개해드리는 위시켓은 2019년 시밀러웹 방문자 수 기준, 국내 1위 IT아웃소싱 플랫폼입니다. 현재 8만 이상의 개발업체, 개발 프리랜서들이 활동하고 있으며, 무료로 프로젝트 등록이 가능합니다. 프로젝트 등록 한 번으로 여러 개발업체의 견적, 포트폴리오, 예상기간을 한 번에 비교해보세요:)

거리를 지나가다 들은 노래가 마음에 들었던 적이 있나요? 가사도 가수도 제목도 모르는데 음만 기억이 나서 답답한 적이 있나요? 당신은 혼자가 아닙니다.
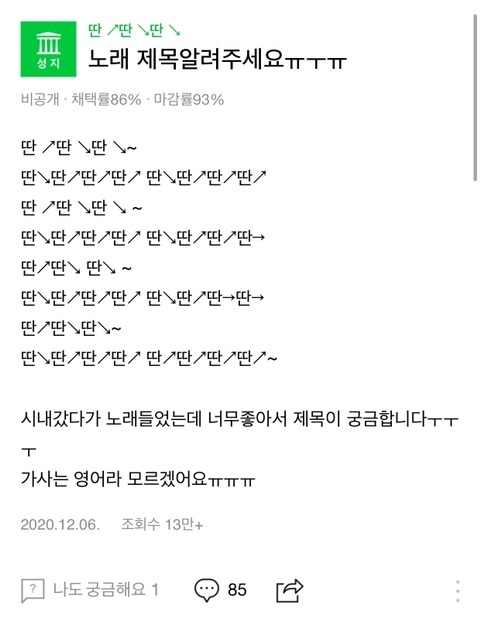
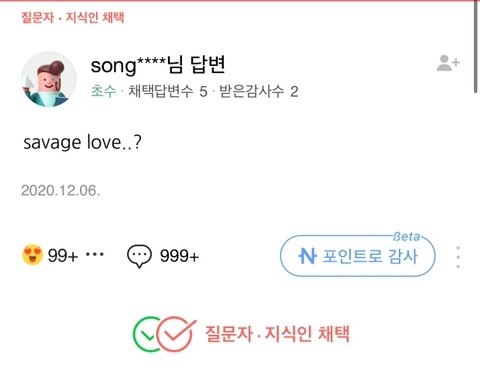
시내 한복판을 지나가면 수많은 노래들이 섞여 들립니다. 운이 좋게 좋아하는 노래를 만나면 찾아서 다시 듣고 싶습니다. 그런데 소음 때문에 노래 검색도 잘 안 먹히고, 노래가 끝나면 노래를 찾을 수 있는 방법은 가사뿐입니다. 그런데 가사가 잘 들리지도 않았다면? 아무래도 음으로 “나~나나~나” 흥얼거려서 알아내는 것이 가장 정확할 것 같은데 찾을 방법이 없습니다.
그래서 지난 ’20년 10월, 구글이 나섰습니다. “흥얼거려서 노래 찾기 (hum to search)”서비스가 바로 그 해결책입니다. 흥얼거려서 노래 찾기 서비스 뒤에 있는 AI를 파헤쳐봅시다.
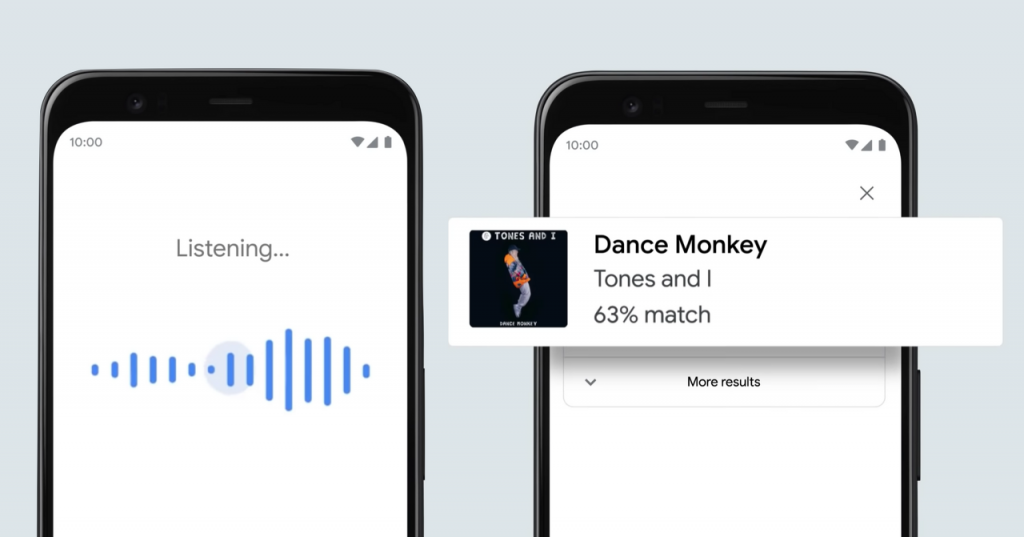
흥얼거려서 찾는 것이 어려운 이유
“흥얼거린” 노래는 실제 음원과 가사, 배경 보컬, 악기 모두 다릅니다. 부른 사람의 해석을 거친 버전이기 때문에 음의 높이, 음조, 빠르기, 리듬도 다르죠. 때문에 기존의 “흥얼거려서 노래 찾기” 서비스는 사용자의 흥얼거림을 원본 음원이 아닌 멜로디만 있거나 흥얼거린 음원과 대조했습니다. 하지만 이렇게 하면 대조할 수 있는 음원이 제한적이고 수동으로 업데이트를 해야 한다는 단점이 있습니다.
그래서 구글은 이렇게 해결했습니다

Photo by Kelly Sikkema on Unsplash
구글의 “흥얼거려서 노래 찾기”는 100% 머신 러닝 서비스입니다. 기존 서비스와 다르게 음악의 스펙트럼에서 곧바로 멜로디의 임베딩을 생성합니다. 임베딩이란 음원 간의 유사도를 판단하기 위해 음원 별로 부여한 값입니다. 앞으로는 임베딩을 “값”으로 표현하겠습니다.
이렇게 하면 음원에서 멜로디만 추출하거나 흥얼거린 음원을 따로 만들 필요 없이 사용자의 흥얼거린 멜로디를 비교할 수 있습니다. 대조할 음원의 DB를 따로 업데이트하지 않고도 최신 음원까지 찾아낼 수 있습니다.
머신 러닝 배경
기존의 음원 인식 시스템은 잘 맞는 음원을 찾기 위해 음원을 스펙토그램 형태로 변환합니다. 흥얼거린 음원이 원본 음원보다 정보가 적다는 문제가 있습니다. 아래 예시는 “Bella Ciao”라는 노래의 흥얼거린 음원(좌)과 원본 음원(우)의 스펙토그램입니다. 모델에 좌측 이미지가 입력되면 그에 맞는 우측 이미지를 5,000만 개가 넘는 비슷하게 생긴 이미지들을 중에서 찾아야 합니다. 인식 모델은 주요 멜로디에 집중하고 배경 보컬, 악기, 음색, 울림의 차이를 무시해야 합니다.
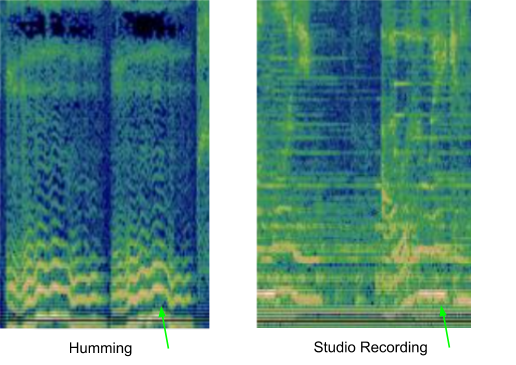
흥얼거린 노래와 원본 음원 스펙토그램 비교
머신 러닝 구성
신경망에 한 쌍의 데이터를 입력합니다.
1) 흥얼거린 오디오, 2) 원본 음원 오디오
그리고 각 데이터에 대한 값을 생성합니다. 값이란 음원 간의 유사도를 판단하기 위해 음원 별로 부여한 수치를 의미합니다.
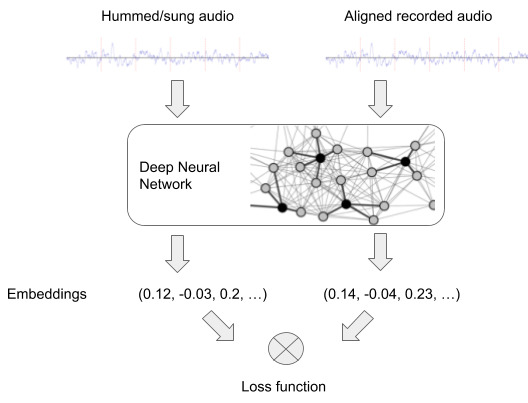
신경망을 위한 학습 구조
흥얼거림을 인식하기 위해 같은 멜로디를 가진 음원에게는 악기나 목소리가 다르더라도 가까운 값을 생성해야 합니다. 다른 멜로디의 오디오 쌍은 먼 값을 생성합니다. 신경망이 이러한 값을 생성해낼 때까지 데이터가 제공됩니다.
학습된 시스템은 원본 음원의 값과 유사한 곡의 값을 생성할 수 있습니다. 그 후 정확한 음악을 찾는 것은 원본 음원 DB에서 유사한 값을 검색하는 것뿐입니다.
요약하자면 AI가 원본 음원과 흥얼거린 노래의 유사도에 따라 특정 값을 부여합니다. 그리고 사용자가 흥얼거린 노래의 값과 유사한 값의 음원을 찾습니다.
데이터 학습
모델 학습에 한 쌍의 데이터가 필요했기 때문에 (녹음과 흥얼거린 버전) 첫 번째 과제는 충분한 학습 데이터를 수집하는 것이었습니다. 처음 수집한 데이터는 너무 적었고, 특히 흥얼거린 노래는 거의 없었습니다. 데이터를 확장하기 위해 음원의 높이와 속도를 무작위로 분화시켰습니다. 결과적으로 모델이 사람들이 부른 노래는 잘 인식했지만 흥얼거리거나 휘파람을 부는 것은 잘 인식하지 못했죠.
흥얼거린 멜로디의 음원 인식 성능을 강화하기 위해 우리는 사람들이 부른 노래를 “흥얼거림”으로 바꾸어 추가로 학습시켰습니다.
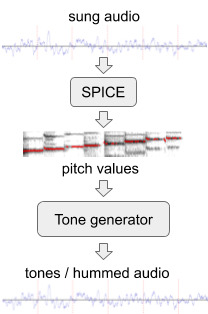
부른 노래를 흥얼거린 노래로 바꾸는 과정
머신 러닝 개선
“흥얼거림으로 검색하기” 모델을 학습시키기 위해 삼중 손실 함수로 시작했습니다. 이 함수는 이미지와 녹음된 음악 분류(classification)에 높은 성능을 보이는 것으로 알려져 있습니다.
같은 멜로디를 두 오디오 (R과 P)가 있을 때, 삼중 손실 함수는 다른 멜로디로부터 온 학습 데이터를 무시합니다. 이는 다른 멜로디가 이미 R과 P로부터 멀리 떨어져 있어 쉬운 케이스(E 예시)와 다른 멜로디임에도 가까이 있어 어려운 케이스 (H 예시) 모두에 대해 기계의 학습 행동을 개선합니다.

우리는 추가 학습 데이터(점 H 및 E)를 고려함으로써 모델의 정확성을 향상할 수 있다는 것을 발견했습니다. 모델이 지금까지 살펴본 모든 데이터를 올바르게 분류할 수 있는지 또는 현재 기준에 맞지 않는 예를 본 적은 있는지 얼마나 확신할 수 있을까요? 이러한 신뢰의 개념을 기반으로 모든 값의 신뢰도를 100%로 끌어올리는 손실 함수를 추가했고 AI의 정확도와 재현율 (precision and recall)이 개선되었습니다.
삼중 손실 함수로 서로 다른 멜로디의 음원을 분류합니다. 그리고 이미 다르게 분류된 음원의 값까지도 학습해 정확도를 끌어올렸다는 것으로 해석할 수 있습니다. 
구글의 “흥얼거림으로 검색” 서비스 뒤에 있는 AI에 대해 알아보았습니다. 지금까지의 내용을 쉽게 네 줄로 요약할 수 있습니다.
- 구글은 ’20년 10월 “흥얼거림으로 검색”하는 서비스를 출시했다.
- 기존 서비스와 다르게 최신 곡까지도 검색이 가능하다.
- 구글이 흥얼거림을 음원의 멜로디가 아닌 원본 음원 자체와 대조했기 때문이다.
- 이는 AI가 흥얼거린 음원과 원본 음원을 한 쌍의 데이터로 학습해 가능했다.
이렇게 구글이 검색의 대상을 음원에서 흥얼거림까지 넓혔습니다. 실제로 흥얼거려서 노래 검색을 시도했던 사람으로서 “흥얼거림 검색 서비스”는 사용자의 니즈를 만족시키는 서비스라고 생각합니다. 다만, 음성 검색을 실행하고 “search a song”라는 버튼을 한 번 더 눌러야 검색이 가능한 것은 접근성이 떨어집니다. 구글의 기존 음원 검색 서비스를 사용했던 사람이라도 “흥얼거림 검색 서비스”가 출시된 것을 알기 어렵습니다.
음악을 좋아하는 사람들에게 유용한 서비스인데, 서비스 홍보와 UX가 개선되면 사용자에게 더 많은 도움을 줄 수 있을 것으로 보입니다.
참고자료: 흥얼거려서 노래 찾기 (hum to search) 서비스
국내 1위 IT아웃소싱 플랫폼, 위시켓이 궁금하신가요?